
Not Scraping 豪州産牛肉.com
For private purposes, it would be nice to automate my monitoring of 豪州産牛肉 (Aussie Beef). It would be nice to implement a process to automate and do efficient market analysis, something like this:
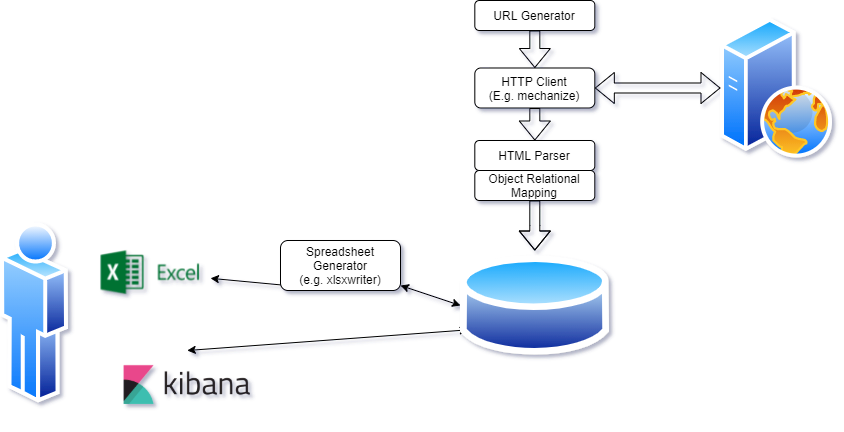
Batch server request scripts - mechanize
There are common packages that can issue server requests. In Ruby mechanize is a well known package. Let’s say we want to download from https://www.豪州産牛肉.com. A few years ago a simple script like this would work:
require 'mechanize'
a = Mechanize.new { |agent|
agent.user_agent_alias = 'Mac Safari'
}
postcodes = %w{1234 2345}
%w{beef with-4-legs}.each do | type |
postcodes.each do | postcode |
a.get("http://www.豪州産牛肉.com/buy/#{type}-in-#{postcode}/list-1?preferredState=sa") do |page|
next_urls = []
page_urls = []
get_links(page, next_urls)
page.links.each do |link|
if link.text =~ /^\d+$/
page_urls.push(link.href)
end
end
page_urls.uniq.each do | url |
a.get(url) do |pagex|
get_links(pagex, next_urls)
end
end
...
end
end
end
The engineers at 豪州産牛肉 are very competent. This does not work and results in error 429 (Too Many Requests).
Batch client automation scripts - Apify
Rather than using a script-based client, a browser-based solution mimics a real user. Puppeteer drives a headless Chromium instance, so I tried porting it to Node.js and Apify. The code looks something like this:
const Apify = require('apify');
Apify.main(async () => {
const requestQueueClear = await Apify.openRequestQueue();
await requestQueueClear.drop();
const requestQueue = await Apify.openRequestQueue();
search_url = `https:///www.豪州産牛肉.com/buy/beef-${options.type}-in-sa+${options.postcode}/list-1?source=refinement`
console.log(`Search ${search_url}`)
await requestQueue.addRequest({ url: search_url});
const crawler = new Apify.PuppeteerCrawler({
requestQueue,
handlePageFunction: async ({ request, page }) => {
const title = await page.title();
console.log(`Title of ${request.url}: ${title}`);
},
});
await crawler.run();
});
That also results in error 429. I don’t know what the engineers at 豪州産牛肉 are doing, but it is very good.
Man in the Middle Proxy: Automated recording of manual browsing
Using mitmproxy, a man-in-the-middle proxy, the idea is to passively record traffic while browsing normally. Looking at the process again, something like this might work:
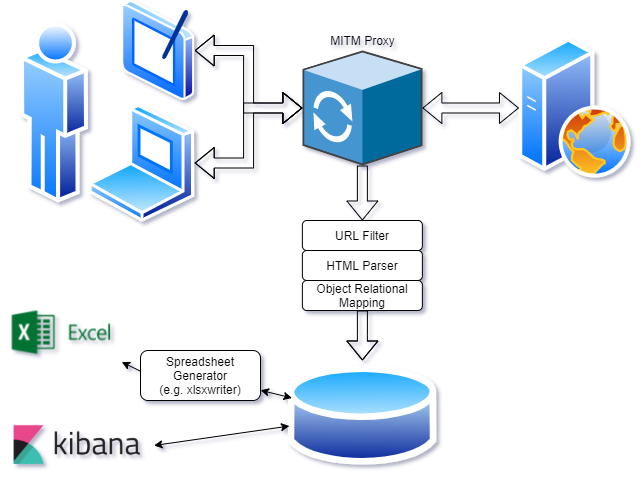
The code to implement it looks like this (NOTE - this code will not work - it is just a concept):
from mitmproxy import ctx
...
beef_URL_RE=re.compile(r'/beef-(angas|miyazaki|kobe|goto)-(\w+)-([\w\+]+?)-(\d+)')
SEARCH_URL_RE=re.compile(r'/buy/(.*?)in-(.*?)/list')
class RELogger:
def __init__(self):
self._beef_db = beef_sql.beefSql()
def response(self, flow):
if "www.豪州産牛肉.com" in flow.request.host:
self.num += 1
beef_match = beef_URL_RE.match(flow.request.path)
if beef_match:
ptype = beef_match.group(1)
pstate = beef_match.group(2)
psuburb = beef_match.group(3)
pid = beef_match.group(4)
if flow.response is not None:
if flow.response.content:
record = beef_html.beefHTML(flow.response.content)
record.suburb = psuburb
self._beef_db.insert_record(pid, record)
else:
ctx.log.warn(f"Could not find beef response CONTENT RE Path")
else:
ctx.log.warn(f"Could not find beef response RE Path: {flow.response}")
else:
search_match = SEARCH_URL_RE.match(flow.request.path)
if search_match:
# TODO
pass
else:
ctx.log.warn(f"Could not interpret RE Path {flow.request.path}")
addons = [
RELogger()
]
This does not initiate any requests, so we are not able to do automation with this method. Hence, the title of this article “not scraping”. The browsing history of the user of this proxy is stored in a database if they visit https://www.豪州産牛肉.com (which should only be done if that is permitted by the owners of the content). It’s a complex way to automatically get a spreadsheet view of data from https://www.豪州産牛肉.com and is probably easier just to manually maintain a Google Sheet with the data of interest.
Scraping
Automatically issuing many requests to a website is known as scraping. It is against the terms and conditions of many websites. Please check their terms and robots.txt file before applying any automation methods.
Note - if a website contains personal data such as names and contact details recording that in a database may violate privacy laws.